Topics
Earliest Forms of Data Science
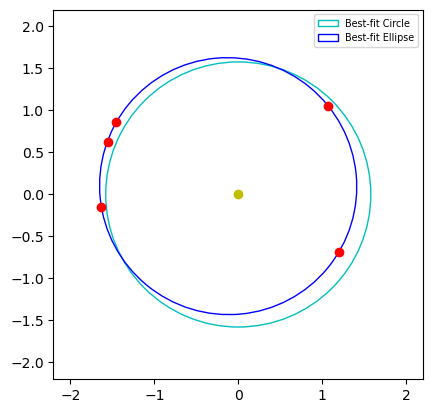
Although the term “data science” was not used until the 20th century, Johannes Kepler used techniques which could be described as a ‘primitive’ form of data science in his work on planetary motion. Kepler used the naked-eye observations of Tycho Brahe to fit the orbit of Mars to a geometric model, discovering that planetary orbits were elliptical rather than circular, and subsequently deriving his famous three laws of planetary motion.


18th and 19th Century
Similarly to the 16th century, the term “data science” within the context of the 18th and 19th century physics may not be entirely accurate. Nevertheless, the scientific advancement of the 19th century undeniably saw an increase in the size of data able to be collected in experiments. Furthermore, the unification of electricity and magnetism in the theory of electromagnetism in the latter half of the century can in some ways be viewed as the precursor to all forms of digital computing and the way we store and access information.

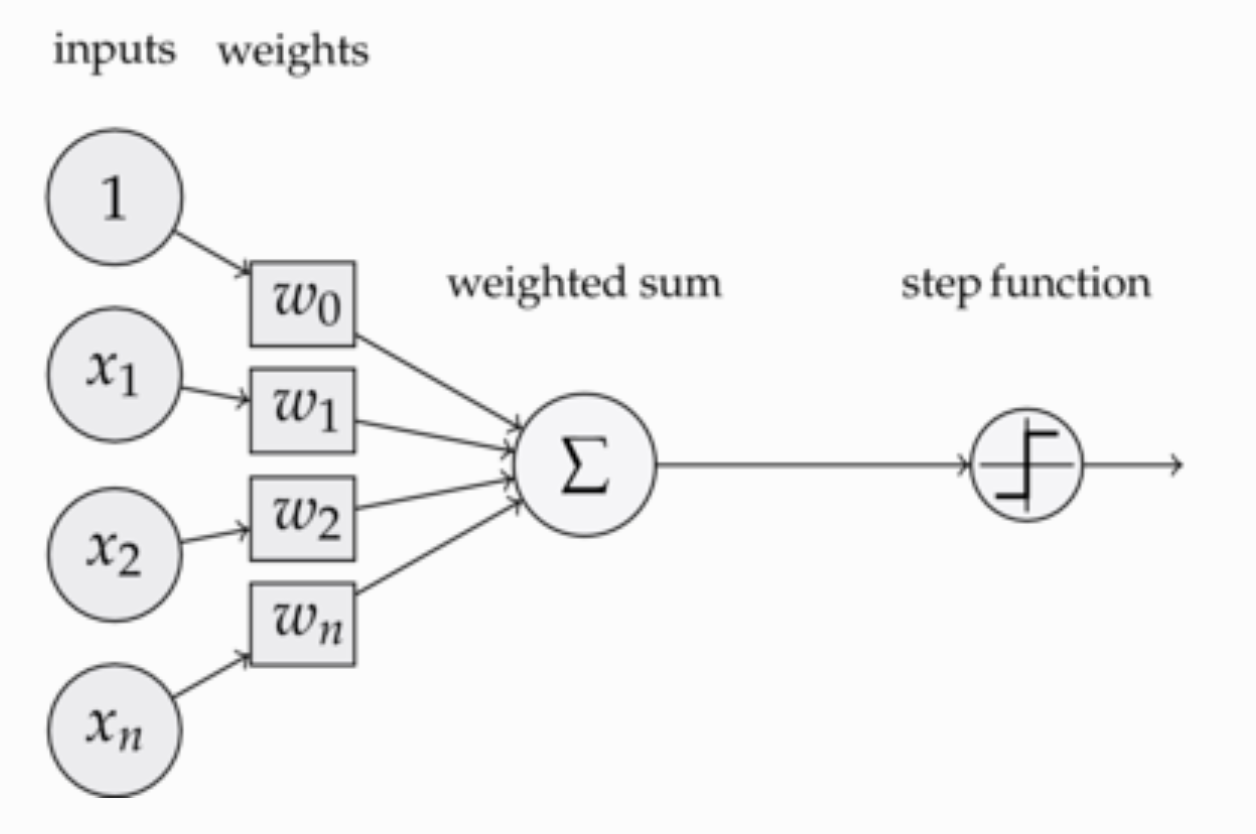
20th and 21st Century
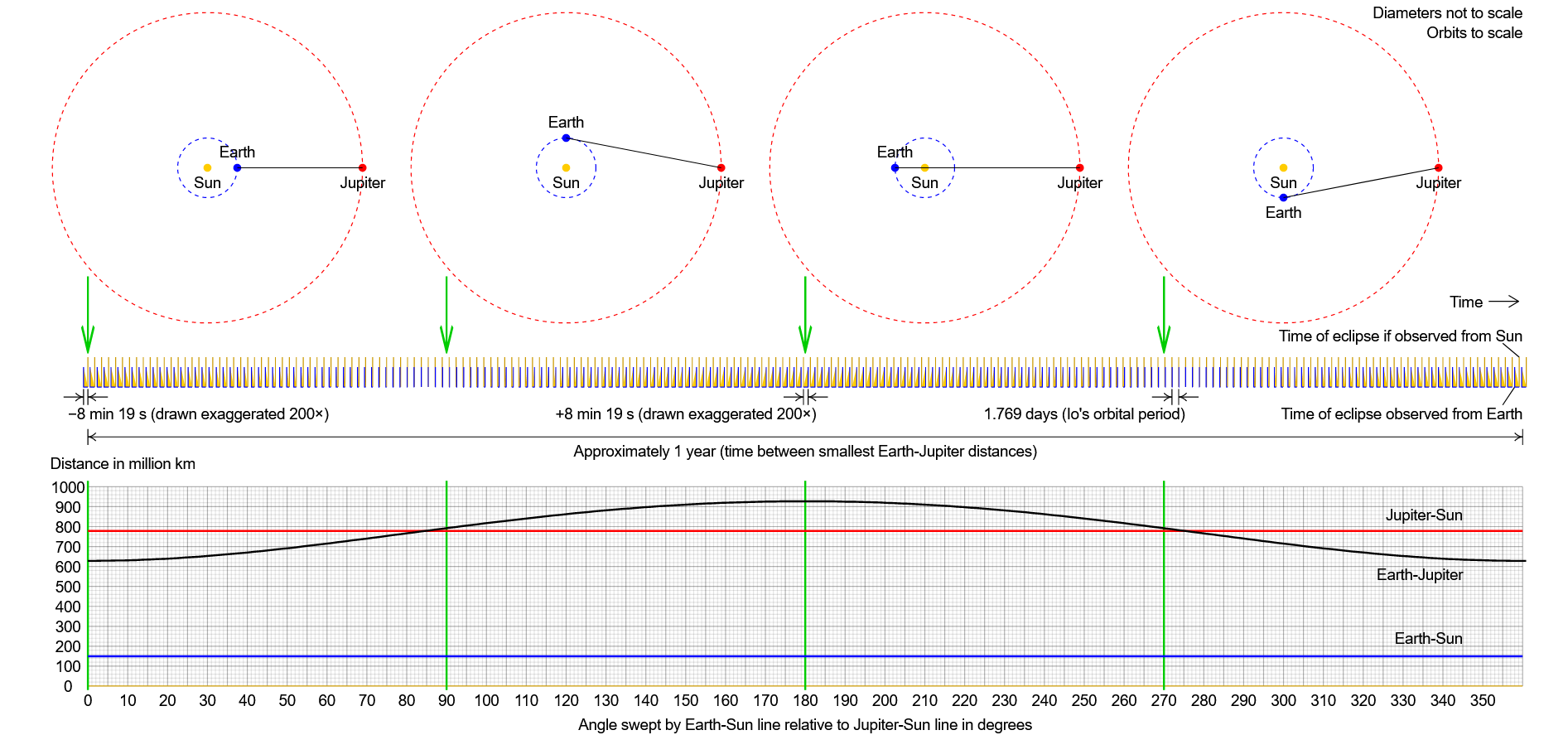
The wide-scale adoption of the computer sparked an unprecedented wave of research in communication and information technology. As a result of suddenly being able to share vast amounts of data across the globe, science has been able to pursue the largest experiments in its history. Experiments such as those in the LHC collect more data in a year than any single person can make sense of in their lifetime, prompting scientists to use the most advanced data processing and analysis techniques to extract meaningful information from these large oceans of data. Furthermore, the field of data science is continuously generating more efficient algorithms that are slowly reaching noteworthy levels of artificial intelligence in many different domains.

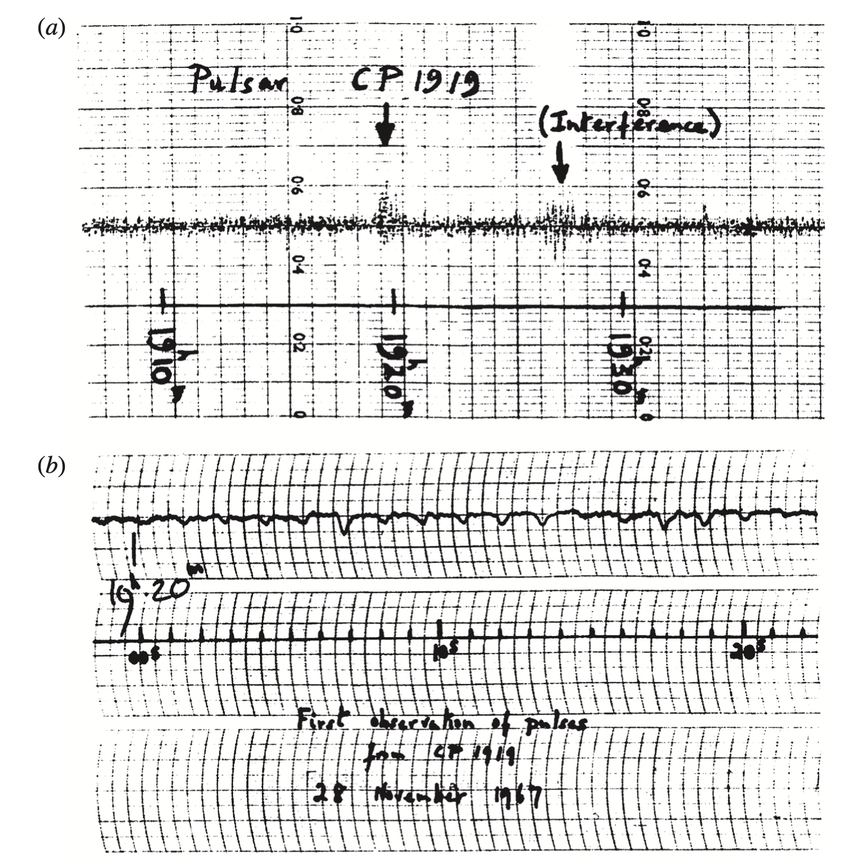
Data Visualisation in Time Series Analysis
Visualisation is an essential component of data science and machine learning. It is used to emphasise patterns, structures, and outliers hidden within large quantities of numerical data. The aim is to communicate key insights obtained through data analysis in a visual and intuitive way, such that they can be easily understood by other scientists, business professionals, managers, and even the general public.

Machine Learning for Classification Tasks
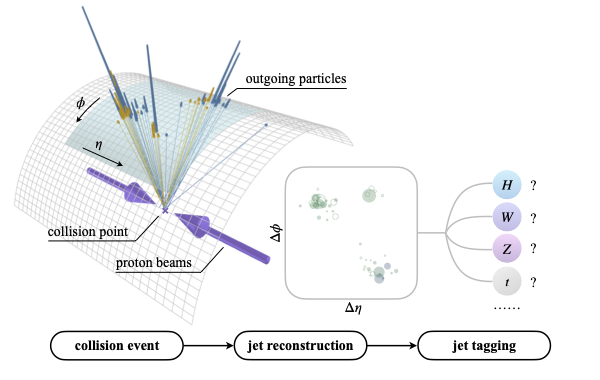
One of the most widespread use cases of machine learning in science is classification, i.e. the problem of assigning parts of the dataset to their correct categories. A simple example often used in computer vision is the classification of images of hand-written digits. While a seemingly simple problem, models used for data classification can learn surprisingly detailed representations of the data they are presented with and may be used to speed up the rate of data processing. In physics, a notable use case is the classification of different particle signals from the Large Hadron Collider.

Data Storage
The incredible achievements of data science in physics and beyond would not have been possible without effective methods for data cleaning and storage. Each of the periods discussed so far have used many different forms of data storage, from physical notebooks (pre-20th century) to magnetic tapes (20th century) and all the way to hard drives (1950s-present) that are able to store incredible amounts of data in relatively compact devices. The development of better storage methods remains an active area of research.
